What did the news say about corporations' sustainability actions?
Izzat · Thursday, February 15, 2024

An overview of my master’s thesis: evaluating companies based on their environmental, social, and governance (ESG) performance by leveraging artificial intelligence.
Background
Sustainability has become a crucial topic in corporate finance, there has been a remarkable shift in investors’ focus from short-term profits to the long-term impacts consideration as well as the non-financial risks [1]. The ESG concept has surfaced as a fresh paradigm, and become a trend in asset management. This novel concept influenced investment behaviors, navigating investors not solely relying on financial returns, but also on emotional and ethical factors that resonate with their moral values [2]. Assessing a company’s sustainability performance has become a pivotal factor in investment decision-making. Renowned organizations like MSCI, Sustainalytics, and Refinitiv offer ESG ratings that evaluate companies based on a variety of metrics. Nevertheless, despite their growing influence, their methodologies have received a number of critiques for determining a company’s commitment and efforts [3, 4, 5, 6].
This study explored a different approach to measuring the efforts performed by enterprises by incorporating a third-person perspective—as opposed to evaluating sustainable reports produced by companies—particularly through news sources. The news media plays an integral role in directing public attention and shaping perception and knowledge about the topics [7]. Prior studies have shown that the mass media has the ability to influence in terms of ESG context [8, 9]. Not only does the mass media drive public perception, but it also urges ESG transparency that mitigates the information asymmetry [9].
Nevertheless, collecting unstructured, scattered, and vast information can be arduous and financially demanding. Using natural language processing (NLP) can alleviate this problem and serve as a supportive tool to streamline the process. Considering the considerable influence of news, my work seeks to investigate the analysis of news articles as a means to evaluate the ESG performance of companies, utilizing NLP models to dissect the expansive data.
The Approach
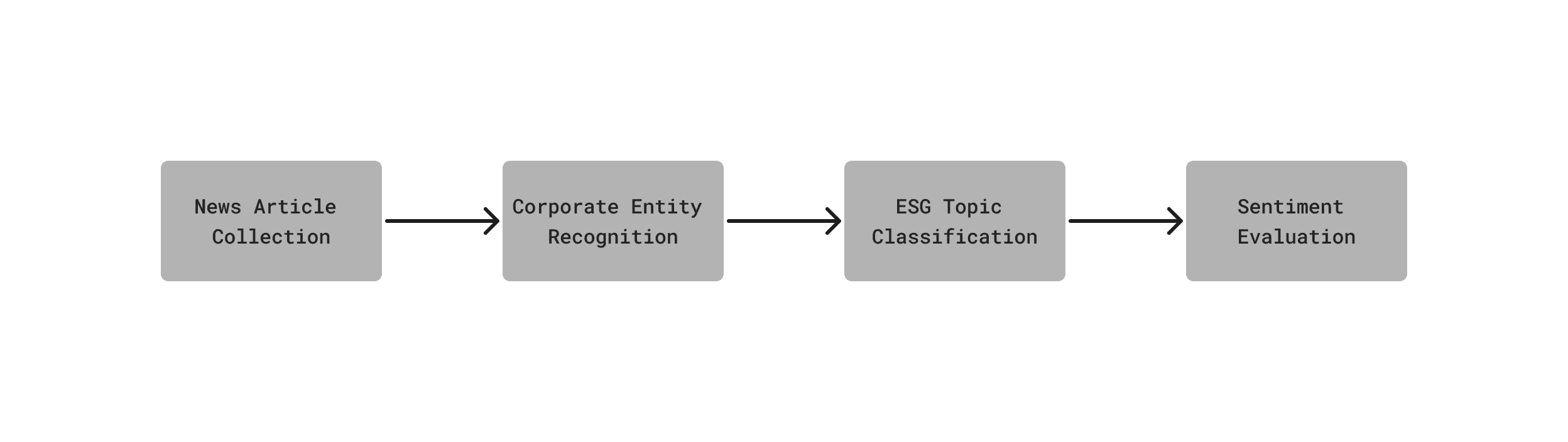
In this study, I employed a machine learning pipeline with a variety of models. It starts with data collection from the news outlet to scoring the performance based on sentiment analysis. For the corporate entity recognition, I applied the named entity recognition (NER) library by spaCy, specifically using the en_core_web_md package, version 3.6.0. For topic classification, I fine-tuned a GPT model, trained with my own customized data. In the last part, I utilized FinBERT by Huang et al. (2023) to classify the sentiment of the articles. The chart below illustrates the proposed pipeline.
Diving deeper into ESG topic classification tasks, I was interested in exploring GPT capabilities to do classification tasks. There are many studies that have developed ESG classification models based on BERT, but there were only a few discussed GPT models. In this part, I specifically prepared my own dataset to train the base model. The dataset was built upon the GDELT project that monitors news media from all over the world in over 100 languages. GDELT offers different datasets for different purposes, and I leveraged the GDELT Article List database, which provides the headline and lead paragraph or summary of the articles.
From the GDELT Article List database, I gathered news pieces from several prominent media outlets, including the Wall Street Journal, Los Angeles Times, Bloomberg, Business Insider, the Economist, Forbes, and the Washington Post. Since the New York Times provides an open API to retrieve news directly, I used its historical articles to evaluate the ratings of companies at a later stage. In total, I manually annotated 4,500 articles, divided equally into nine fine-grained topics of ESG. The nine classes are inspired by MSCI ESG Key Issues with minor adjustments, namely ‘Climate Change,’ ‘Resource Stewardship,’ ‘Environmental Opportunities,’ ‘Human Capital,’ ‘Product Liability,’ ‘Social Opportunities,’ ‘Corporate Governance,’ ‘Business Ethics,’ and ‘Non-ESG.’
A series of experiments was conducted to achieve optimal configuration for the fine-tuned model. There were two key techniques: the inclusion of a prompt in the input and the application of a dummy label in the output, which led to four distinct combinations:
- (a) A version without any prompt and using the original label
- (b) A version without any prompt but introducing the dummy label
- (c) Incorporating the prompt while sticking to the original label
- (d) Incorporating the prompt and introducing the dummy label
See the table below for the illustration.
| Model | Input | Output |
|---|---|---|
| (a) | CEO of UK-based energy supplier Drax shares how the company, formerly 100% reliant on coal, reduced its carbon emissions by 85%. The company now has ambitions to not just be carbon neutral, but carbon negative. -> | Climate Change |
| (b) | CEO of UK-based energy supplier Drax shares how the company, formerly 100% reliant on coal, reduced its carbon emissions by 85%. The company now has ambitions to not just be carbon neutral, but carbon negative. -> | baz |
| (c) | Classify the following text into one of the following classes: [' Climate Change', ' Resource Stewardship', ' Environmental Opportunities', ' Human Capital', ' Product Liability', ' Social Opportunities', ' Corporate Governance', ' Business Ethics', ' Non-ESG'] Text:\n'''CEO of UK-based energy supplier Drax shares how the company, formerly 100% reliant on coal, reduced its carbon emissions by 85%. The company now has ambitions to not just be carbon neutral, but carbon negative.''' -> | Climate Change |
| (d) | Classify the following text into one of the following classes: [' baz', ' qux', ' roc', ' tuv', ' dap', ' stu', ' klo', ' xya', ' nop'] Text:\n'''CEO of UK-based energy supplier Drax shares how the company, formerly 100% reliant on coal, reduced its carbon emissions by 85%. The company now has ambitions to not just be carbon neutral, but carbon negative.''' -> | baz |
The dataset was then divided into training and validation sets using an 80:20. I used this dataset to fine-tune the ‘ada’ model from the GPT-3 series, which, unfortunately, is now no longer supported by OpenAI. Each fine-tuning experiment lasted around 25 minutes on average, with a ranging cost of $0.31 to $0.67. Indeed, the (c) experiment costs the most since it needed a longer input.
Results
Fine-Tuning Results
For a starter, let’s discuss the fine-tuning experiments first before diving deeper into the results from running the whole pipeline. During the training, I noticed distinct performance trends for each setup. For instance, the original label gives better results after the first round of training, which might be because the base model already understands the labels. However, a better performance in the first round does not guarantee the best final results because the first (a) setup had the lowest accuracy among all. You can see the accuracy and steps for each model below.
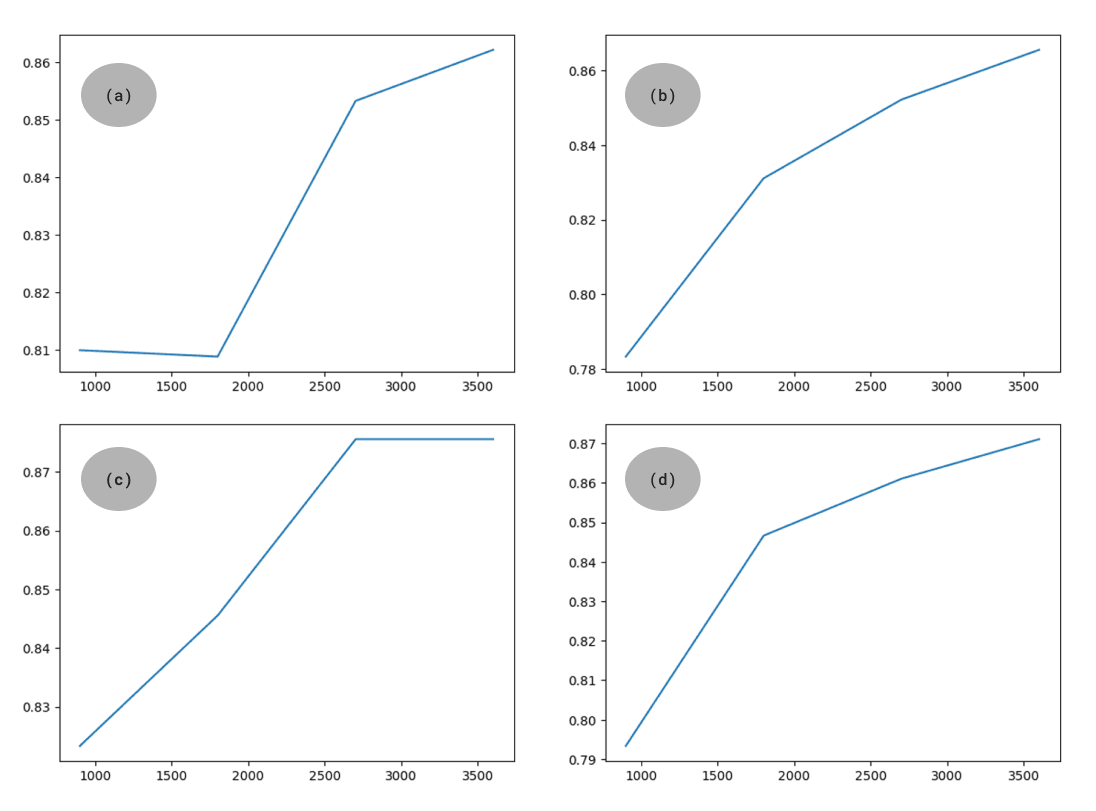
In selecting the preferred fine-tuned model, I leveraged training loss, accuracy, and weighted F1-score to draw insights about the performance of each model. The third (c) experiment demonstrated a superior efficacy with a lower training loss of 0.013 and better accuracy & weighted F1-score of 0.875. While both (c) and (d) were impressive with low training losses, I decided to choose the third model since it offers better accuracy and F1-score. The full comparison can be found in the table below.
| Model | Training Loss | Accuracy | Weighted F1-Score |
|---|---|---|---|
| (a) | 0.021 | 0.862 | 0.862 |
| (b) | 0.024 | 0.865 | 0.865 |
| (c) | 0.013 | 0.875 | 0.875 |
| (d) | 0.012 | 0.871 | 0.871 |
News Analysis
Now, let’s see the pipeline in action. As mentioned earlier, I retrieved the news collections from the New York Times, spanning from 2003 to 2022. The headlines and lead paragraphs are extracted and then combined as input for further analysis. For the case study, I leveraged this pipeline for eight diverse companies from three distinct industries: four technology giants (Apple, Microsoft, Alphabet, and Meta), two top beverage enterprises (The Coca-Cola Company and PepsiCo), and two pharmaceutical firms (Pfizer and Johnson & Johnson).
The spaCy’s NER library worked really well in detecting the organization’s name. Nevertheless, the coverage is distributed disproportionately between the companies. The technology sector, with its massive market capitalization, garnered overwhelmingly more attention than other sectors. Each technology company had no less than a thousand pieces, while the highest amount for other sectors was less than 500.
The fine-tuned model then did its action for those selected articles, of which only 4.879 items were left after excluding the non-ESG ones. Each sector owned unique characteristics in terms of the topics it was covered. With regard to ethical concerns, the beverage and pharmaceutical companies were more scrutinized for their unethical marketing and advertising tactics, while the technology companies were mainly criticized for their anticompetitive behavior. On a different side—regarding the social aspects, the media appreciated the contributions of Pfizer and Johnson & Johnson in providing COVID-19 vaccines and their breakthrough in improving public health. In contrast, reports highlighted the hypocrisy of beverage companies, for example, when they donated millions to health groups while simultaneously spending big cash to oppose health legislation.
It is regrettable that the environmental topics were not well-covered compared to other ESG topics for all companies. The efforts were underappreciated, and there were only a handful number of critics. Even for the technology sector, which garnered thousands of articles, there was only a small fraction in the environmental theme—only around 1-3%. Only the beverage sector received a higher share of media coverage concerning this matter, exceeding 10% of all topics.
I observed the prevailing sentiment expressed in news articles about the ESG performance of companies is dominated by a neutral tone, which might be due to several reasons. First thing, the outlet tends to maintain an unbiased viewpoint. Another reason is perhaps the model employed in this study has an inherent bias toward classifying sentiments as neutral. It is important to note that the model was primarily trained on financial communication texts instead of texts specifically focused on ESG aspects. Another limitation of the sentiment analysis arose from the lack of integration between the company on the text and the sentiment. The sentiment analysis only captured the overall tone, while the text might have a different perspective toward the company in question. See the example below.
The model classified this text as ‘Negative,’ which was aligned with the overall tone that shows a hassle in their efforts. Nevertheless, the company in question was actually committed to fighting for it, a potentially positive effort. Integrating the sentiment into the entity can enhance the accuracy of a company’s sentiment. The entity-level sentiment analysis method is proficient at untangling the complex layers of sentiment related to various entities within a text.
Conclusions
The significant impact of media on public perception inspired me to explore their role in providing information about the ESG efforts of corporations. I proposed a machine learning pipeline to assess a company’s performance based on the articles. The results of this study show different characteristics in media reporting for the respective sector. The different nature of each sector’s activities might be the rationale for these differences. I also wanted to highlight that the coverage of the environmental aspects of the company as well as reportage for smaller companies, should be increased to inform the public about the undertaking of corporations to become more sustainable.
On the other hand, the machine learning pipeline indeed has improved the workflow for the analysis, sorting hundreds of thousands of scattered articles into meaningful insights. The entity recognition model by spaCy and the fine-tuned model for topic analysis worked very well in classifying the news pieces into relevant topics. Nonetheless, improvement in the sentiment analysis can result in a more accurate assessment of companies’ actions.
If you want to read the full report, you can access it here.
References
[1] Krappel, T., Bogun, A., & Borth, D. (2021). Heterogeneous Ensemble for ESG Ratings Prediction.
[2] Hartzmark, S. M., & Sussman, A. B. (2019). Do Investors Value Sustainability? A Natural Experiment Examining Ranking and Fund Flows. The Journal of Finance, 74(6), 2789–2837.
[3] Ilango, H. (2023, May 2). An unregulated ESG rating system reveals its flaws. Institute for Energy Economics & Financial Analysis.
[4] Allen, K. (2018, December 6). Lies, damned lies and ESG rating methodologies. Financial Times.
[5] Chatterji, A. K., Durand, R., Levine, D. I., & Touboul, S. (2016). Do ratings of firms converge? Implications for managers, investors and strategy researchers. Strategic Management Journal, 37(8), 1597–1614.
[6] Berg, F., Kölbel, J. F., & Rigobon, R. (2022). Aggregate Confusion: The Divergence of ESG Ratings. Review of Finance, 26(6), 1315–1344.
[7] McCombs, M., & Reynolds, A. (2002). Media Effects (J. Bryant, D. Zillmann, J. Bryant, & M. Beth Oliver, Eds.). Routledge.
[8] Brown, N., & Deegan, C. (1998). The public disclosure of environmental performance information—a dual test of media agenda setting theory and legitimacy theory. Accounting and Business Research, 29(1), 21–41.
[9] Hammami, A., & Hendijani Zadeh, M. (2019). Audit quality, media coverage, environmental, social, and governance disclosure and firm investment efficiency. International Journal of Accounting & Information Management, 28(1), 45–72.